Scalable Support Request Analysis Using Embeddings, HDBSCAN, and Tiny LLMs

Jijo P
Effective use of historical data to classify support requests into buckets and identify emerging or slightly different patterns.

Data Exploration:
Analyze the historical data to understand data quality, recurring key phrases, noise, and other patterns. Also examine meta-attributes such as manual tagging, assigned department, assigned personnel, etc.
Data Cleansing and Enrichment:
Identify domain-specific non-relevant words and create regex rules to remove them. Identify possible aliases and create regex rules for standardization.
For product-related support requests, the same product may be referred to using different terms; these can be masked with a common placeholder such as product. Identify other words or phrases that may need masking as well.
This will help the machine learning algorithm improve accuracy and avoid unnecessary cluster formation caused by irrelevant variations.
Apply to Dataset:
Keep one copy of the raw data before applying the cleansing and enrichment steps. After applying the transformations, review the effectiveness of the processed data and make any necessary adjustments. Once everything is validated, embed the data into vectors using open-source embedding models. Select the appropriate model based on the domain data. Few examples in the below screenshot

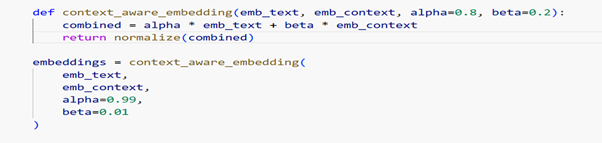
Context Weightage:
In some scenarios, we may need to provide additional weightage to certain keywords or phrases based on the domain and the nature of the data. To achieve this, identify those key phrases and create a standardized string representation for each row record. Then generate a separate vector embedding for this context.
Create a new function to combine the row data vector (alpha) and the context vector (beta), where a configurable parameter can be used to adjust the relative weightage between them.
Identify a Suitable ML Algorithm for Clustering:
The HDBSCAN algorithm provides an effective approach for clustering, as it can identify clusters of varying density and also classify noise points as a separate group. Adjusting the parameters is critical for achieving good results. Therefore, perform multiple iterations and experiments to identify the most suitable parameter settings for the specific use case.

Noise Cluster Drilldown:
Based on the data volume and parameter settings, there is a possibility that the algorithm may generate more noise data than expected. In such scenarios, it is better to perform a drill-down clustering on the noise data by reducing the min_cluster_size parameter. This will help generate another set of buckets with smaller clusters.
Generate Title and Short Description Using an LLM:
Once the two levels of clusters are identified, use a small LLM to generate a title and a short description for each cluster. You can either use an LLM that can run on a CPU or use OpenAI or any other subscription-based LLM service.

Incremental Data or New Request Row Data:
After building the clustering model using historical data (ensure that prediction_data: true is enabled), new records can be validated against the existing clusters using HDBSCAN prediction and cosine similarity. Based on the results, the new request can be assigned to the appropriate cluster or categorized as noise.

Outer Layer or Slightly Different from the Core Cluster:
Define a scale to identify close and distant probability values within each cluster. A value of 1 represents 100% probability, and such records will be the centroid data of the cluster. Values between 0.01 and 0.49 indicate records that are farther away or have a lower probability of belonging to the core of the cluster. These records may represent emerging trends or requests that are slightly different from the centroid pattern.

Conclusion:
The above approach helps eliminate most LLM-related costs and is highly feasible for processing large datasets. The risk of hallucination is also limited, as the solution does not rely entirely on an LLM. When implementing this in a production-level system, it is important to continuously evaluate the noise data and determine when a complete re-creation of clusters is required, especially after a significant number of new records have been incrementally assigned over time
We can help!

Optimizing Legacy Applications: Effective Strategies For Tco Reduction
#Applicationre-engineering

Optimizing Relational Databases: Sql Server & Postgresql
#Applicationre-engineering

Assess Current Database Environment: A Crucial Step In Database Migration
#Applicationre-engineering